


What’s Going on in China AI? Deepseek, Manus, and their Impact on NVIDIA (NVDA US) Demand

笔者并不是AI算法方面的工程师,但最近中国在AI模型方面的发展,从上个月崛起的Deepseek到这个月的新星Manus,的确对AI芯片的需求(至少是中国区的需求)有着巨大的影响,因此今天笔者就试着根据自己目前的理解来简单分析一下它们对AI算力需求的潜在影响。
首先,让我们来尝试分析一下Deepseek的优化算法对NVDA芯片需求所带来的负面影响。这里主要讨论三个Deepseek所采用的技术:MLA (multi-head latent attention),MTP(multi token prediction),以及Sparse MoE(mixture of expert)。
我们知道,大模型在进行预测时,需要使用任意两个token之间的关系作为预测依据。Deepseek之前的大模型大多采用MHA (multi head attention)的方法,其核心思想即是通过多个维度来表示两个token之间的关系,而非单一标量。例如,一个维度可能用于表示两个token是否属于同一种语言,另一个可能用于表示它们在语义上的关联性,还有一个可能用于判断它们是否存在逻辑否定关系等。通过这种多维度表征,可以更全面地捕捉两个token之间复杂且多样化的关联信息。在主流的大型模型中,通常会设置10~30个heads,以确保足够丰富的信息表达能力。
而来自中国的Deepseek由于缺少GPGPU的算力,采用了一种MLA (multi-head latent attention)的方法,即在矩阵中只保留最关键的一些特征向量,从而减少要计算的tokens数。举个可能过于简化的例子(不考虑low-rank joint compression 和RoPE计算量):比如对于100个tokens的输入序列,传统的大模型要求每个token与其余99个tokens进行关系计算;而MLA方法则将原本100个tokens的序列压缩成仅保留~5个最重要的特征向量,再对这5个特征向量进行矩阵计算,这样减少了~95%的计算量。懂行的人可能会问:理论上来说,注意力的主要成本是O(n2d), n是序列长度,n从100降低到5,减少的计算量不是(1002-52)/1002 = 99.75% FLOPs吗?但是实际工程中,考虑到筛选关键特征向量也需要计算,或者采用多层分段聚合也会付出一些算力,前馈网络/ 归一化层这些的优化等等,所以实际不会达到99.75%,能达到~95%就极其可观了。
接下来,我们还要引入KV Cache(key-value cache)的概念。我们做硬件的人都知道,整个AI算力除了GPGPU本身,最大的瓶颈其实在HBM(high bandwidth memory),而这就牵涉到KV Cache。KV cache是一种用于存储attention机制中key和value值的数据结构。在大模型预测下一个token时,需要计算当前token与之前所有tokens之间的关系,这涉及到用当前token对应query(Q)值查找之前所有tokens对应key(K)值,并根据强关联程度提取value(V)值。因此,为了加速访问,这些key和value需要存储在极易访问的位置(比如HBM)。KV cache复杂性的来源包括:每一层中的key和value都会发生变换,因此需要为每层单独存储;且如果存在多个head,则需按per layer,per head,per token分别存储key和value。
因此,在HBM容量受限的条件下,Deepseek的MLA (multi-head latent attention)技术可以通过对key和value进行压缩,从而减少KV cache所需的存储空间。但需要注意的是,虽然MLA会减少推理时的HBM用量,但并不会减少训练时的HBM用量。这是因为:在训练阶段,KV cache并非HBM的主要存储内容,HBM主要用于存储模型参数、优化器状态、梯度、词表(例如多模态模型中token词表可达数百万级别)等。其中优化器状态占用最大内存,且与模型的参数量强相关,一般为参数量的3~5倍。以经典的 Adam 优化器中为例,每个参数除了自身的权重以外,还需要存储 “一阶矩(动量)” 和 “二阶矩(方差),再加上一些额外的辅助状态,所以是3-5倍。例如,对于Deepseek R1 671 billion模型的参数量,如果极限假设以int8格式存储,每个字节乘以5即可估算出优化器状态所需占用的存储空间。在实际情况中,大规模模型仍然需要至少局部(如动量/方差)使用Float16/32等相对高精度,以保持数值稳定性,减少梯度爆炸/消失,所以可能会高于这个估算;而在推理阶段不需要存储优化器状态和梯度,因此相较于训练阶段,在采用了MLA技术之后的确可以节省一部分内存(主要针对KV cache而言 )。然而,如果Deepseek以后开发出native多模态模型,其词表可能需要扩大10~20倍,这将抵消一部分KV cache对HBM内存节省的效果。
接下来,让我们来看一下Deepseek所采用的另外一项技术:MTP(multi token prediction)。所谓multi token prediction,顾名思义即是让模型一次性预测接下来好几个tokens。目前业界实测下来一次预测后5个tokens以内为最佳方案,超过5个准确度就已经很差了。在实际使用中,DeepSeek选择了一次预测后2个tokens,这带来的结果是:相比于一次预测1个token,一次预测2个tokens后对浮点运算的算力需求大致减少了30%。这里不是减少了50%,是因为一次tokens预测结果不好还要返回去做,这一部分也要消耗不少算力。此外,MTP对减少数据传输延迟也有一定帮助:相比于原来1个token发一次数据包,现在2个tokens发一次数据包,整体发的数据包的次数就只有原来的1/2,这样减轻了交换器要路由的数据阻塞程度。
最后,笔者再来解释一下Deepseek所采用的Sparse MoE架构。在Deepseek之前,传统的大模型尝试用的都是Dense MoE架构,即MoE(mixture of expert)的专家数量相对较少但每个专家的规模较大。例如每层可能包含100个专家,每次激活80个,这种方式无需复杂的路由优化即可实现稳定的性能。而Deepseek的Sparse MOE架构则采取相反策略,即拥有大量小型的专家,但每次仅激活少量专家。例如100个专家中只选8个激活,要确定挑选哪8个专家就需要另一个gating model来决定每个token应该分配给哪些专家。这种方法也有助于节省算力需求。
然而,Sparse MOE架构的缺点也显而易见:由于每次专家的激活数量有限,一些专家可能长期未被训练,导致训练不充分问题。为解决这个问题,需要引入平衡网络,通过人为手段确保在训练阶段专家分配尽可能均匀,并对不均匀的分配施加惩罚;此外,在推理阶段,如果某些tokens频繁访问特定已训练充分的专家,会造成这些专家节点成为瓶颈。为此Deepseek发明了EPLB(专家并行负载均衡器)技术,即在实际推理时对高负载的专家多复制几个,动态地使用GPGPU资源来分配使用专家。
下面,让我们以中国为例来测算一下Deepseek的这一整套优化算法对NVDA芯片需求所带来的影响:
这里笔者假设在乐观情形下,中国未来所有的城镇常住人口(~9亿人)都将习惯于每天使用AI大模型的chatbot来进行上网搜索,即DAU为9亿;另外假设chatbot的DAU并发比例为1%,则并发数为9亿 x 1% = 9百万个。
由NVDA最近公布的对Deepseek R1模型的实测数据可知(DeepSeek-R1 Now Live With NVIDIA NIM),NVDA H200卡在以FP8精度做推理时的tokens吞吐量为484 tokens/ second。而Deepseek官方公布的数据显示其tokens的平均输出速率为20~22 tokens/ second。由此我们可以计算出每张NVDA H200卡每秒可以同时处理484 / 21 = 23个并发,则9百万个并发需要9mn / 23 = 39万张NVDA H200卡支持。
同理,Deepseek官方公布的数据显示,经过一整套优化方案之后其所使用的NVDA H800卡(即中国特供版卡)在以FP8精度做推理时的tokens吞吐量为1850 tokens/ second。由此我们可以计算出其每张NVDA H800卡每秒可以同时处理1850 / 21 = 88个并发,则9百万个并发需要9mn / 88 = 10万张NVDA H800卡支持,与上文中没有采取Deepseek优化方案相比所需卡数减少了将近~75%!
但是,以上还不是今年中国AI start-up公司给业界带来的全部surprise。仅仅几周前,另一家来自中国的AI公司Manus发布了一款极其流畅的AI agent产品,不仅在业界引起了不小的反响,也让投资人们开始思考:在可预见的未来,一款流行的AI agent产品可能会为AI算力需求带来多大的正面影响?在这里,笔者仅提供一个大致地思路,供读者朋友们参考。
Manus AI agent的处理流程如下图所示:
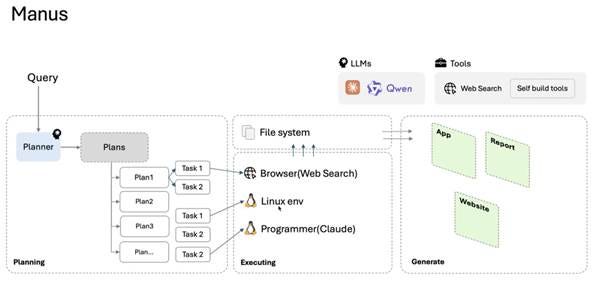
当一个用户的query进来后,先会有一个planner模型产生一个母版,并将其分解成一步步的plans,每个plan当中又包含了好几个tasks。每个task则会调用不同的功能(比如web browser, Linux系统,Claude programming)来完成每个分步的任务,并产出该任务相对应的文件放到一个文件系统当中(这里需要沙盒系统),以便于用户之后回溯查看每个分步任务的结果。最后,由于Manus整合了Claude的编程功能,整个AI agent最终的output可以根据用户的自定义而做成不同的形态(比如app,文档report,网页等)。
这里的一个重点是,由于整个流程中通常包含了几十个小tasks,其中不少tasks是需要调用视觉大模型来进行浏览器页面的截图和操作,而视觉模型相比文本模型来说其所需要的算力(以tokens/ second为单位)是成数量级增长的。我们在前文中提到过Deepseek的chatbot平均tokens输出速率为~21 tokens/ second,而一个视觉agent则可能会需要500~1000 tokens/ second。当然,Manus并不是一款纯视觉agent,而是一个文本和视觉agent的结合体,因此笔者保守假设Manus的平均tokens输出速率为~200 tokens/ second。这样,同样一张经过Deepseek一整套优化方案之后的NVDA H800卡每秒只可同时处理1850 / 200 = 9个并发。
不仅如此,用户实测Manus的案例显示它的AI agent完成一个复杂任务通常需要20~30分钟的时间 vs. chatbot一个query的处理时间仅有4~5分钟。因此,理论上用户使用Manus的query并发比例也会比chatbot高5~6倍。这里笔者假设使用AI agent的DAU并发比例为5%(即5x于现在的chatbot)。中国的白领人口大约为2亿人,假设未来这些白领全部成为DAU,则AI agent的并发数为2亿 x 5% = 1千万个。中国WPS(相当于Microsoft Office的中国版)月活已经超过6亿,所以这个假设并不激进。由此我们可以计算出这些并发总共需要10mn / 9 = 110万张NVDA H800卡的支持,与前文中Deepseek chatbot的case相比所需卡数增加了将近~10x!
由此可见,虽然Deepseek的一整套优化算法把大模型推理对AI算力的需求下降了~75%,但Manus所代表的AI agent又揭示了未来推理所需的AI算力还将增长~1000%,因此net-net未来的AI算力需求还是会大幅增长。当然,这里我们需要问的一个问题是:AI agent究竟何时才能成为一个在大众中普及的常用app?笔者的观点偏乐观,相信以中国software engineers的迭代速度,在不久的未来在中国一定能诞生出一款成熟的AI agent爆款应用。
特别鸣谢笔者的一位多伦多大学的好友对本文所做出的贡献:)
相當贊同作者不斷擴展知識範圍, 當以AI晶片為中心點, 往上游分析(供應商, 供應產能), 再往下游分析(CSP, AI模型, AI Agents), 會逐漸碰到PE/ 管理顧問常用的分析方法論, 用這些不同方法論取得之結論, 又可以返回中心點調整對AI晶片產業的持倉/作多/做空.
大佬 不好意思 可以問 在投資層面上 我們到底該往那些層面去探索? 例如: ASIC, API供應商? 雲服務供應商? RAG供應商?