


Macom (MTSI US) – A Hidden Nvidia GB200 Play (更新版)

笔者在今年四月初OFC conference之后首次发文阐述了美国上市公司Macom在GB200中的新content dollar机会。在此之后,笔者在6月份参加了Computex展会并亲自走访了安费诺及各大GB200 ODM厂商展台。本文即是在6月份笔者实地调研了Macom芯片在GB200中的各大应用场景之后,根据更新后的信息所作的update。
要了解Macom在GB200中的具体content dollar机会,我们首先要对GB200的互联方式有一个初步的了解。Jenson在6月初的大会上show出了下图这张GB200 NVL576 Super Pod(即576个GPU互联)的示意图:

笔者根据实地走访调研了解到,一个标准的NVL576 Super Pod应该由8个NVL72 GB200 racks和4个switch racks组成。上图示意图中只画出了四个GB200 racks(黄/绿色线的柜子),应该还有四个GB200 racks在后面的那一排(从示意图中隐约可以看到后面两个GB200 racks背面的cable cartridge)。在前排四个GB200 racks的右手边则并排排放了四个switch racks(蓝色线的柜子),这些柜子里放的都是IB switches用来做东西向流量的连接。每个GB200 rack里面会有9个NVL switch trays通过backend的cable cartridge连接18个compute trays做in rack间的72 GPUs互联(注意NVL switch trays本身并没有frontend panel,所以机柜间的GPU互联必须走compute trays的frontend network)。此外,每个GB200 rack顶部还会放一台ToR switch,用来做南北向流量的连接。细心的读者朋友可能发现了上图中GB200 racks的左手边还有一个蓝色线的switch rack,但这个交换机柜并不参与NVL576 Super Pod的GPU互联,而是一个用来支持其他机柜里miscellaneous network的switch rack(比如debug network, in-band management network等)。
讲完top down level的network布局,让我们再从bottom up level看一下单个GB200 compute tray的network layout(见下图):
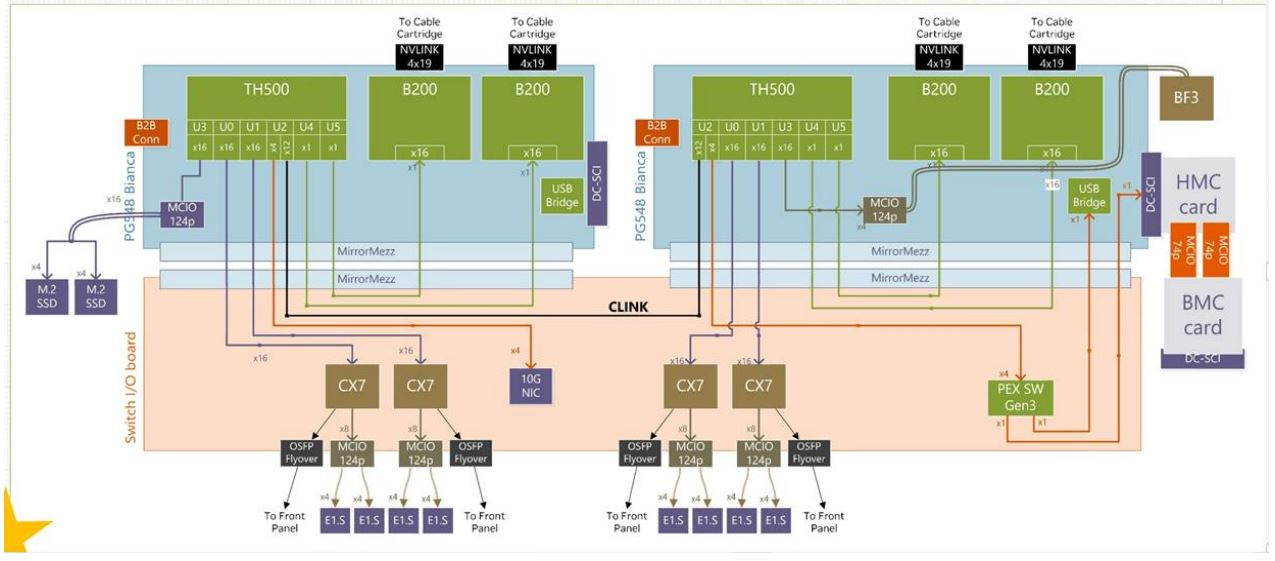
上图是一张标准的GB200 Bianca compute tray的简单示意图。我们可以看到每个compute tray里面配有四个backend network端口,通过cable cartridge连接到GB200 rack中间的9个NVL switch trays。Frontend network则通过四张网卡(图中目前为显示CX7网卡,明年实际量产的GB200则会升级成为CX8网卡)搭配四个OSFP端口连接到第一层的交换机网络。按照明年的量产规格,笔者假设标准的frontend network采用的是四张CX8网卡配四个800G的OSFP端口用于连接东西向流量,其中NVDA规定必须采用IB交换机,且必须以1:1的收敛比进行组网。本文以最大三层组网为例,简单解释一下NVL576 Super Pod的东西向流量组网架构:其中第一层网络是由每个GB200 compute tray的四个frontend 800G OSFP端口经光纤连接到旁边switch racks里的IB交换机上。每根光纤的一端(compute tray)连的是两个800G的LPO模组,另一端(IB switch)连的是一个1.6T的DSP模组,再分叉接在Quantum X800 IB交换机的两个800G端口上。Quantum X800 IB交换机总共有144个800G端口,则简单计算可知要组网成576个GPU互联,按照1:1的收敛比总共需要576/(144/2)=8个第一层交换机,8个第二层交换机,以及576/144=4个第三层交换机。其中第一层与第二层交换机都是72个端口负责下行网络,72个端口负责上行网络,第三层交换机的144个端口则全部都是下行网络。每层交换机之间则都是由1.6T的光模块互联。在实际应用过程中,由于1.6T光模块的成本较高,CSP客户会根据需要把不同层级的交换机尽量部署到同一个switch rack当中,这样in rack的switch连接就可以走更便宜的1.6T ACC而不是光模块,从而节省成本。
对于南北向流量的连接,NVDA推荐ToR switch采用以太网交换机搭配800G ACC进行连接。每根ACC的一端分叉连接到compute tray的两个400G OSFP端口(内接两张BF3 DPU),另一端连接在ToR switch的一个800G端口上。NVDA的Spectrum-X800以太网交换机总共有64个800G端口,其中36个端口负责下行网络连接36个compute trays,其余28个端口则留作负责上行网络,根据CSP客户的需求按照一定的带宽收敛比进行组网。以太网交换机之间则可采用800G DSP光模块进行互联。
在这里笔者需要简单解释一下为什么NVDA在GB200 racks里的连接会选择采用ACC或LPO这种非DSP的方案 vs. AEC或传统的DSP光模块(笔者在上一篇讲Credo的文章中介绍了AEC与ACC的区别:Credo (CRDO US) – A Hidden ASIC Server Play):与传统DSP相比,ACC和LPO这种纯模拟器件具有延时小、功耗低、散热性能好的优势,特别是对于AI服务器集群而言,信号传输的延时问题和散热问题都是两大头疼的难题。传统DSP模块导致的信号传输延时约为200纳秒,而模拟器件可将延时控制在5纳秒,这对于AI服务器的大规模数据训练和推理具有显著优势。同样地,拿掉DSP之后,LPO模块的功耗可以比DSP模块节省将近一半,而这就大大降低了对散热的要求。因此NVDA才会在GB200中首推以前被业界认为是非主流产品的ACC和LPO方案。
理解了GB200的互联方法,我们就可以测算出Macom在其中具体的content dollar机会了。根据笔者的了解,Macom在NVDA GB200中总共提供四种不同的产品:1.6T以及800G ACC里的linear equalizer,800G LPO模组里的TIA+driver,和1.6T DSP光模块里的driver。后文我们进行详细的阐述。